

Adding the DISTINCT keyword to a SELECT query causes it to return only unique values for the specified column list so that duplicate rows are removed from the result set. Since DISTINCT operates on all of the fields in SELECT's column list, it can't be applied to an individual field that are part of a larger group. That being said, there are ways to remove duplicate values from one column, while ignoring other columns. We'll be taking a look at a couple of those here today.
The Test Data
In order to test out our queries, we'll need a table that contains duplicate data. For that purpose, I added some extra emails to the Sakila Sample Database's customer table. Here's a screenshot in Navicat Premium's Grid view that shows a customer that has 2 associated emails:
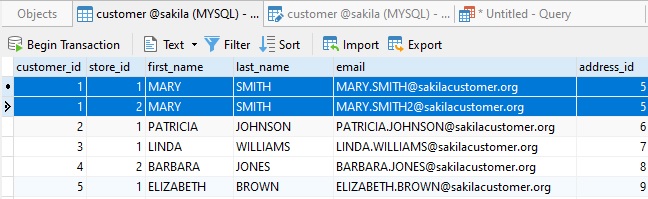
If we were now to add the DISTINCT clause to a query whose field list contains other columns, it does not work because the row as a whole is unique:
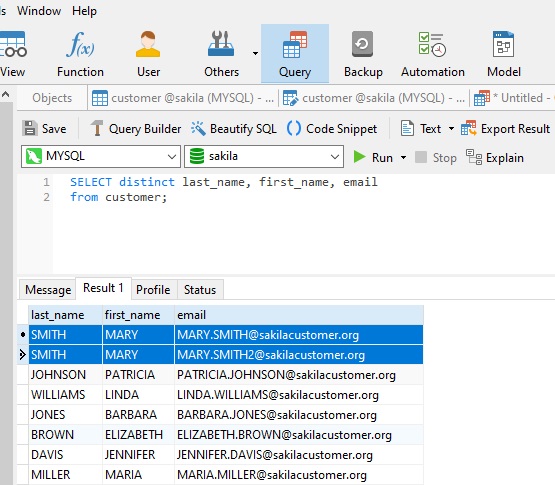
So, what does work? Let's find out!
Using Group By
The GROUP BY clause applies aggregate functions to a specific subset of data by grouping results according to one or more fields. When combined with a function such as MIN or MAX, GROUP BY can limit a field to the first or last instance, relative to another field.
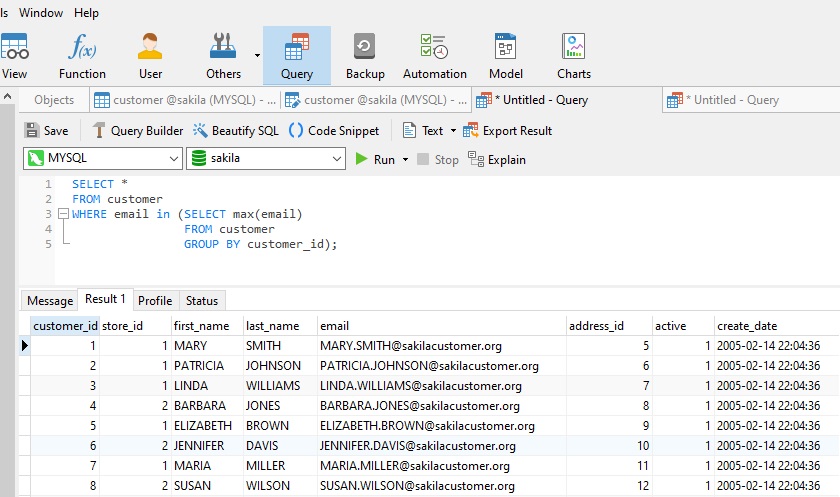
Therefore, if we wanted to limit emails to one per customer, we could include a sub-query that groups emails by customer_id. We can then select other columns by joining the email column to the unique ones returned by the sub-query:
Using a Window Function
Another, albeit slightly more advanced solution, is to use a Window function. Window functions are thus named because they perform a calculation across a set of table rows that are related to the current row. Unlike regular aggregate functions, window functions do not cause rows to become grouped into a single output row so that the rows retain their separate identities.
ROW_NUMBER() is a window function that assigns a sequential integer to each row within the partition of a result set, starting with 1 for the first row in each partition. In the case of customers' emails, the 1st email returns 1, the 2nd returns 2, etc. We can then use that value (referenced as "rn" below) to select only the 1st email for each customer.
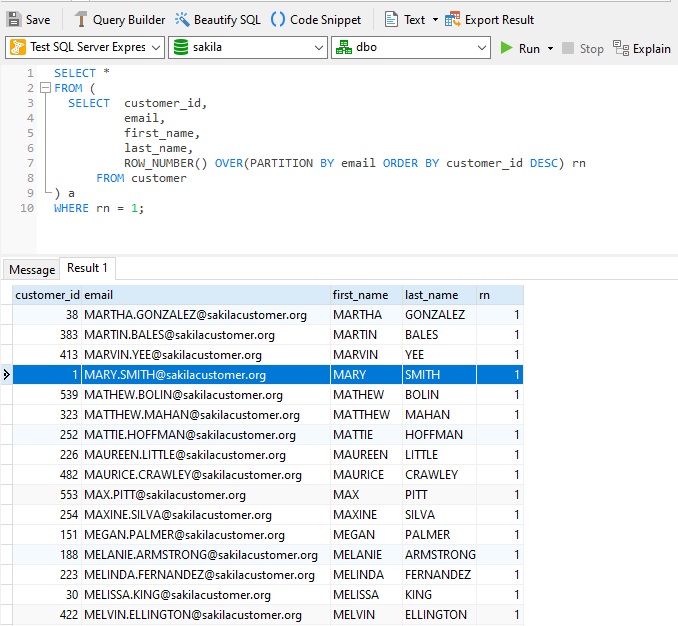
It should be noted that not all relational databases support window functions. SQL Server does support them, while MySQL introduced them in version 8.
Conclusion
In today's blog, we learned how to remove duplicates from individual fields that are part of a larger group using GROUP BY and Windows functions. There are undoubtedly many other ways of achieving the same end goal, but these two tried-and-true techniques should serve you well.
Interested in Navicat Premium? You can try it for 14 days completely free of charge for evaluation purposes!









