

In this series on Collation support in MongoDB, we've been learning how to specify collation in MongoDB using the Navicat for MongoDB GUI administration and development tool. Part I provided a brief introduction to the concept of collation, covered the fields that govern collation in MongoDB, as well as got into some of the specifics of the first three fields, namely Locale, Case Level, and Case First. Today's blog will describe the rest of the fields.
Strength
Our next field, Strength, ascribes the level of comparison to perform.
Possible values include:
- Primary: Collation performs comparisons of the base characters only, ignoring other differences such as accents and case. Hence, å, ä, and a would all be treated as the same character.
- Secondary: Collation performs comparisons up to secondary differences, such as accents. That is, base characters + accents. Note that differences between base characters takes precedence over secondary differences.
- Tertiary: Collation performs comparisons up to tertiary differences, such as case and letter variants. That is, collation performs comparisons of base characters, accents, as well as case and variants. Although English only has case variants, some languages have different but equivalent characters, i.e simplified vs. traditional Chinese. At this level, differences between base characters takes precedence over accents, which takes precedence over case and variant differences.
- Quaternary: Limited to a specific use case to consider punctuation when levels 1 to 3 ignore punctuation or for processing Japanese text.
- Identical: Limited for the specific use case of tie breaker.
This is the default level.
In Navicat, you'll find all of the above values conveniently located in a dropdown list:
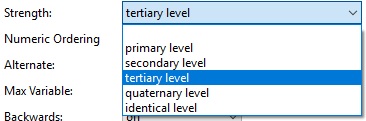
Numeric Ordering
This is a flag that determines whether to compare numeric strings as numbers or as strings:
- If on, compare as numbers; i.e. "10" is greater than "2".
- If off, compare as strings; i.e. "10" is less than "2".
The default is false.
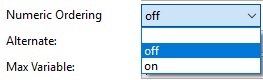
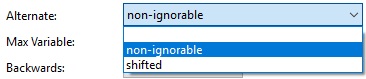
Alternate
This is another simple but powerful field that determines whether collation should consider whitespace and punctuation as base characters for purposes of comparison.
It has only 2 possible values:
- non-ignorable: Whitespace and punctuation are considered base characters.
- shifted: Whitespace and punctuation are not considered base characters and are only distinguished at strength levels greater than 3.
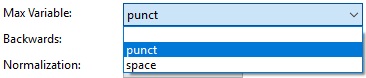
Max Variable
This field determines up to which characters are considered ignorable when Alternate is set to shifted. It has no effect when Alternate is set to non-ignorable.
It has only 2 possible values:
- punct: Both whitespaces and punctuation are "ignorable", i.e. not considered base characters.
- space: Only whitespace are "ignorable", i.e. not considered base characters.
Backwards
Here's another flag. This one determines whether strings with accents sort from the back of the string, such as with some French dictionary ordering.
- If on, compare from back to front.
- If off, compare from front to back.
The default value is false.
Normalization
Our final field is a flag that determines whether to check if text requires normalization and to perform normalization if it does. Generally, the majority of text does not require normalization processing.
- If on, check if fully normalized and perform normalization to compare text.
- If off, does not check.
The default value is off.
Conclusion
Now that we've covered all of the Collation fields, in a future blog, we'll learn how to apply collation rules to your sorting operations in MongoDB.









