

Predicate Evaluation Order
Just before Part 3 of this series, we took a brief pause to talk about Predicates in SQL, as they factored into mistakes related to Outer Joins. In this final installment of this series on Top SQL Query Mistakes, predicates will once again enter the picture, as we examine how predicate evaluation order can cause seemingly well constructed queries to fail with errors.
A Quick Review of Predicate Processing Order
In terms of logical query processing order, queries are executed in the following sequence:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
Hence, logically speaking, the FROM clause is processed first to define the source data set. Next, the WHERE predicates are applied in order to whittle down the result set, followed by GROUP BY, and so on.
In practice, predicate evaluation and processing order is far less rigid, as the query optimizer may move expressions in the query in order to produce the most efficient plan for retrieving the data. As a result, a filter in the WHERE clause may not be applied before the next clauses are processed. In fact, a predicate may be applied much later in the physical execution plan than you might expect.
Another common source of confusion and frustration to database developers is that, unlike with most programming languages, predicates are not always executed from left to right. This means that, if you have a WHERE clause containing the filters "WHERE a=1 AND b=2", there is no guarantee that "a=1" will be evaluated first. In fact, there is no easy way to tell which order filters will be executed simply by looking at the query.
A Practical Example
To better understand predicate evaluation order, we'll write a SELECT query against the following accounts table, seen in Navicat 16's Table Designer:
Here is some sample data that we'll be querying against:
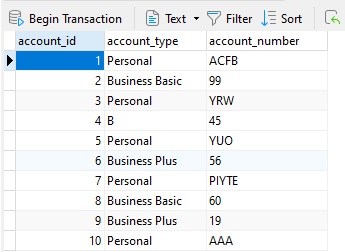
In the account_number column, business accounts are assigned a numeric identifier, while personal accounts are given an identifier made up of characters. This is not great table design, as the account_number column should be represented by two different fields, where each account type is given the correct data type and not share the same table. Nonetheless, altering the design is not always possible, so we must deal with the table as is.
So, with this in mind, let's devise a query to retrieve all business type accounts with an account_number that is greater than 50. The resulting query might look like this one:
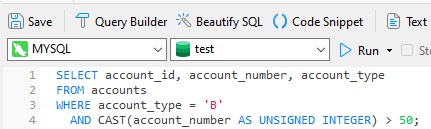
In some databases, the query produces an error:
Conversion failed when converting the varchar value 'ACFB' to data type int
The query will fail any time that the query optimizer decides to prioritize the "CAST(account_number AS UNSIGNED INTEGER) > 50" predicate over the "account_type LIKE 'Business%'". The safest be for avoiding errors like the one above is to either:
- Design the table correctly and avoid storing mixed data in a single column.
OR
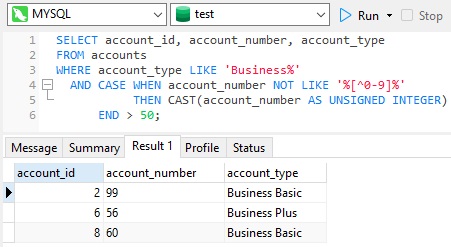
- Use a CASE expression to guarantee that only valid numeric values will be converted to INTEGER data type, like this:
Conclusion
In this series on Top SQL Query Mistakes, we explored how seemingly intuitive ways of constructing SQL queries can result in anti-patterns that lead to erroneous results and/or performance degradation. Be especially wary of predicate placement and evaluation order as these contribute to many unexpected issues.









