

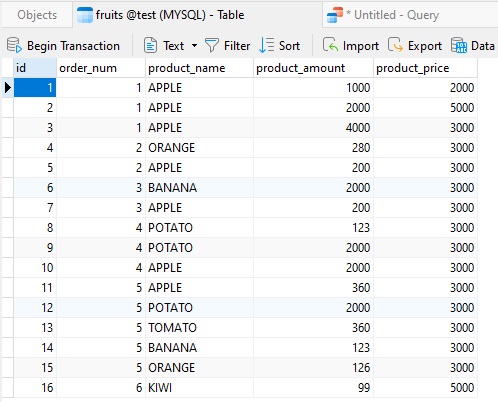
There are many times where you'll want to see the relative contribution of a row (or group of rows) to the total row count. In other words, what percentage of the total count a row represents. To illustrate, let's take the following table, shown in Navicat Premium 16:
Throughout the past several weeks, we've been looking at Navicat 16's new features. While exciting to see, one should not discount the many improvements to Navicat that enhance its already great User Interface (UI) and workflow. Hence, today's blog will focus on improvements whose aim is to maximize performance and productivity.
With all of the excitement surrounding the release of Navicat 16, other noteworthy developments have been overshadowed somewhat. Perhaps none more so that the new standalone Navicat Charts Creator. Charting has been a part of Navicat products for some time now. Navicat 15 went even further to include data visualization in order to help identify trends, patterns and outliers. Navicat 16 adds even more features, by supporting more data sources and chart types as well as a focus on usability and accessibility. Suffice to say, Navicat can deliver information and present your findings in dashboard for sharing to a wider audience than ever before. In today's blog, we'll take a quick tour of Navicat 16's new charting tools.
When the Navicat team added the Navicat Cloud collaboration tool a few years ago, little did anyone know that a global pandemic would make collaboration a vital part of most organizations - especially those who provide any kind of Information technology (IT) related services. Being where we are in the last days of 2021, it should come as no surprise that Navicat has expanded its cloud solutions for Navicat 16. Now, Navicat Cloud supports more objects, and Navicat has just introduced an On-Prem Server for businesses working with sensitive data. Today's blog will provide an overview of Navicat 16's improved collaboration features.
The recent Navicat 16 listed some of its most note-worthy features and improvements, including:
- Data Generation
- Charts
- On-Prem Server
- Collaboration
- UI/UX Improvements
As promised, we'll be exploring these in much more detail throughout the coming weeks. In today's blog, we'll start with the entirely new Data Generation tool. We'll familiarize ourselves with it by going through the process of creating testing data for multiple related tables in Navicat Premium 16 for Windows.




- 2024 (1)
- 2023 (1)
- 2022 (1)
- 2021 (1)
- 2020 (1)
- 2019 (1)
- 2018 (1)
- 2017 (1)









